2.1.1.1.1.14. emicroml.modelling.cbed.distortion.estimation.MLModel
- class MLModel(num_pixels_across_each_cbed_pattern=512, max_num_disks_in_any_cbed_pattern=90, architecture='distoptica_net', mini_batch_norm_eps=1e-05, normalization_weights=None, normalization_biases=None)[source]
Bases:
_MLModelA machine learning model for distortion estimation in CBED.
The current class is a subclass of
torch.nn.Module.A given machine learning (ML) model represented by the current class takes as input a mini-batch of images, where each image is assumed to depict a distorted CBED pattern, and as output, the ML model predicts sets of coordinate transformation parameters that specify the coordinate transformations that describe the distortions of the input images. The coordinate transformation used to describe the distortions of an image is defined in the documentation for the class
distoptica.StandardCoordTransformParams. The parameter set parameterizing said coordinate transformation is referred to as the “standard” coordinate transformation parameter set, and is represented by the classdistoptica.StandardCoordTransformParams.ML models are trained using the
emicroml.modelling.cbed.distortion.estimation.MLModelTrainer.After a ML model has been trained, users should use the method
emicroml.modelling.cbed.distortion.estimation.MLModel.make_predictions()of the current class to make predictions.- Parameters:
- num_pixels_across_each_cbed_patternint, optional
The number of pixels across each imaged CBED pattern stored in the ML dataset used or to be used to train the ML model. This parameter is expected to be equal to the instance attribute
emicroml.modelling.cbed.distortion.estimation.MLDataset.num_pixels_across_each_cbed_patternof the instance of the classemicroml.modelling.cbed.distortion.estimation.MLDatasetrepresenting the aforementioned ML dataset. Moreover, the parameter is expected to be a positive integer that is divisible by2**5.- max_num_disks_in_any_cbed_patternint, optional
The maximum possible number of CBED disks in any imaged CBED pattern stored in the ML dataset used or to be used to train the ML model. This parameter is expected to be equal to the instance attribute
emicroml.modelling.cbed.distortion.estimation.MLDataset.max_num_disks_in_any_cbed_patternof the instance of the classemicroml.modelling.cbed.distortion.estimation.MLDatasetrepresenting the aforementioned ML dataset.- architecturestr, optional
This parameter specifies the network architecture of the ML model. At the moment, only one network architecture is available for this ML model, and it is specified by setting
architectureto"distoptica_net", referring to the DistopticaNet architecture. Below we refer to this network architecture as the DistopticaNet architecture.In short, the DistopticaNet architecture is a custom residual network with 37 non-trivial layers, and downsampling operations being performed using strided convolutions rather than pooling. By a non-trivial layer, we mean either a fully connected layer or a 2D convolutional layer with kernel dimensions other than \(1 \times 1\).
Before describing in more detail the DistopticaNet architecture, it is worth introducing several smaller networks used to construct the architecture.
First, we introduce the residual network building block, defined graphically as:
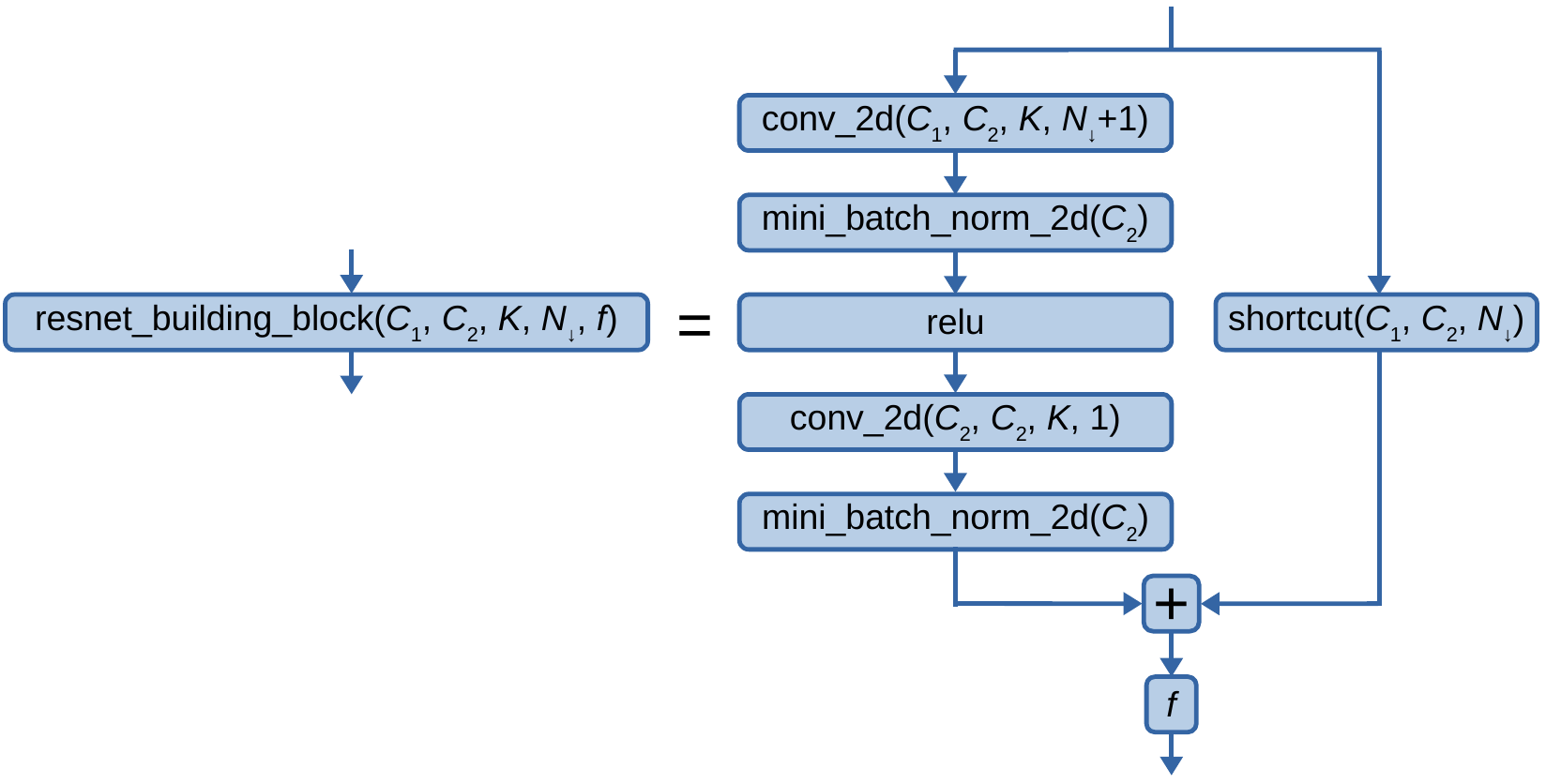
Fig. 2.1.1.1.1.14.1 The residual network building block, where \(C_1\), \(C_2\), \(K\), \(N_{\downarrow}\), and \(f\) are the number of input channels, the number of output channels, the maximum kernel size, the number of downsamplings to perform in the first convolutional layer, and the final activation function respectively.
The above image introduces several mathematical objects: \(\text{conv_2d}\left(C_{1},C_{2},K,S\right)\) is a 2D convolutional layer with \(C_1\) input channels, \(C_2\) output channels, a kernel size of \(K\), a stride of \(S\), a zero-padding width of \((K-1) // 2\) on all sides, all biases fixed to zero, a dilation of unity, and all inputs are convolved to all outputs; \(\text{mini_batch_norm_2d}\left(C\right)\) is a mini-batch normalization layer of 2D inputs with \(C\) input channels; \(\text{relu}\) is the ReLU activation function; \(\text{shortcut}\left(C_{1},C_{2},N_{\downarrow}\right)\) is \(\text{conv_2d}\left(C_{1},C_{2},1,1+N_{\downarrow}\right)\) followed by \(\text{mini_batch_norm_2d}\left(C_{2}\right)\) if either \(C_{1} \neq C_{2}\) or \(N_{\downarrow} > 0\), else it is an identity shortcut connection; \(+\) is the addition operator; \(f\) is an activation function.
Next, we introduce the residual network stage, defined graphically as:
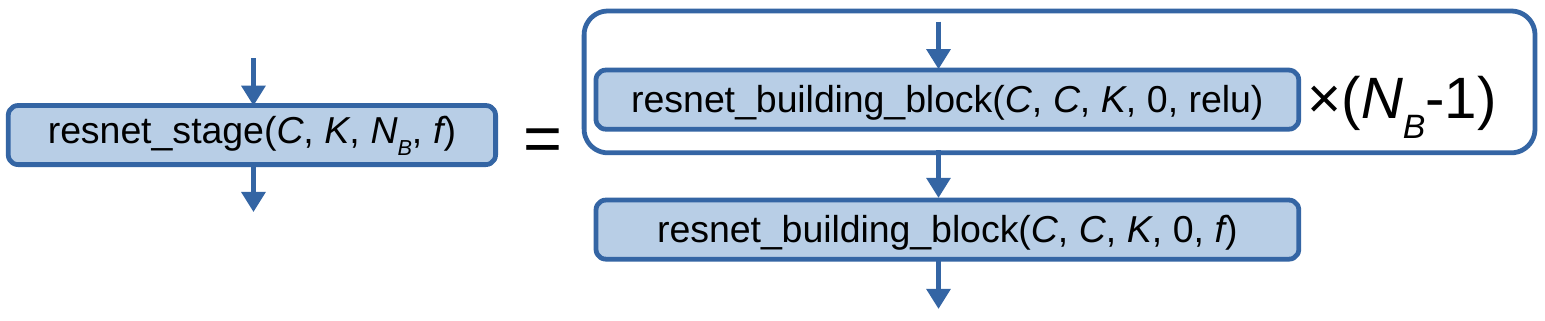
Fig. 2.1.1.1.1.14.2 The residual network stage, where \(C\), \(K\), \(N_B\), and \(f\) are the number of input channels, the maximum kernel size, the number of residual network building blocks in the stage, and the final activation function respectively.
Next, we introduce the “enhance” operation, defined graphically as:
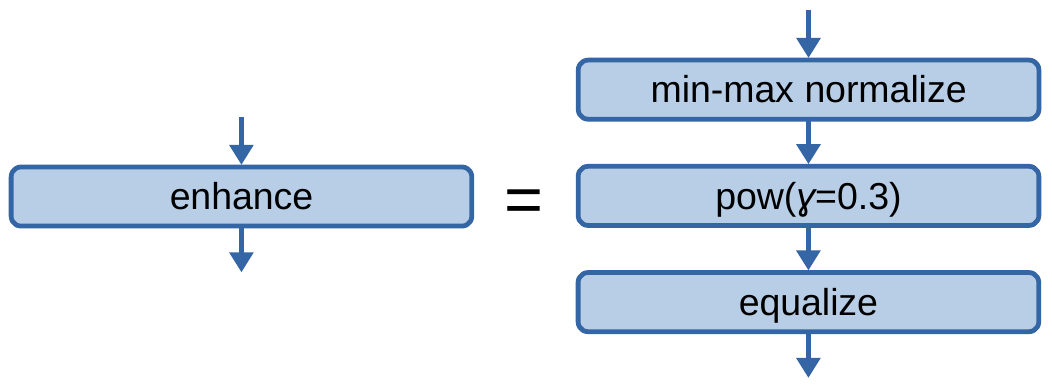
Fig. 2.1.1.1.1.14.3 The enhance operation.
The above image introduces a few mathematical objects: \(\text{min-max normalize}\) is the min-max normalization operation, applied to each image stored in the input tensor of the entry flow; \(\text{pow}\left(\gamma\right)\) is the gamma correction operation with the power-law exponent \(\gamma\); \(\text{equalize}\) is the histogram equalization operation, applied to each feature map.
Next, we introduce the DistopticaNet entry flow, defined graphically as:
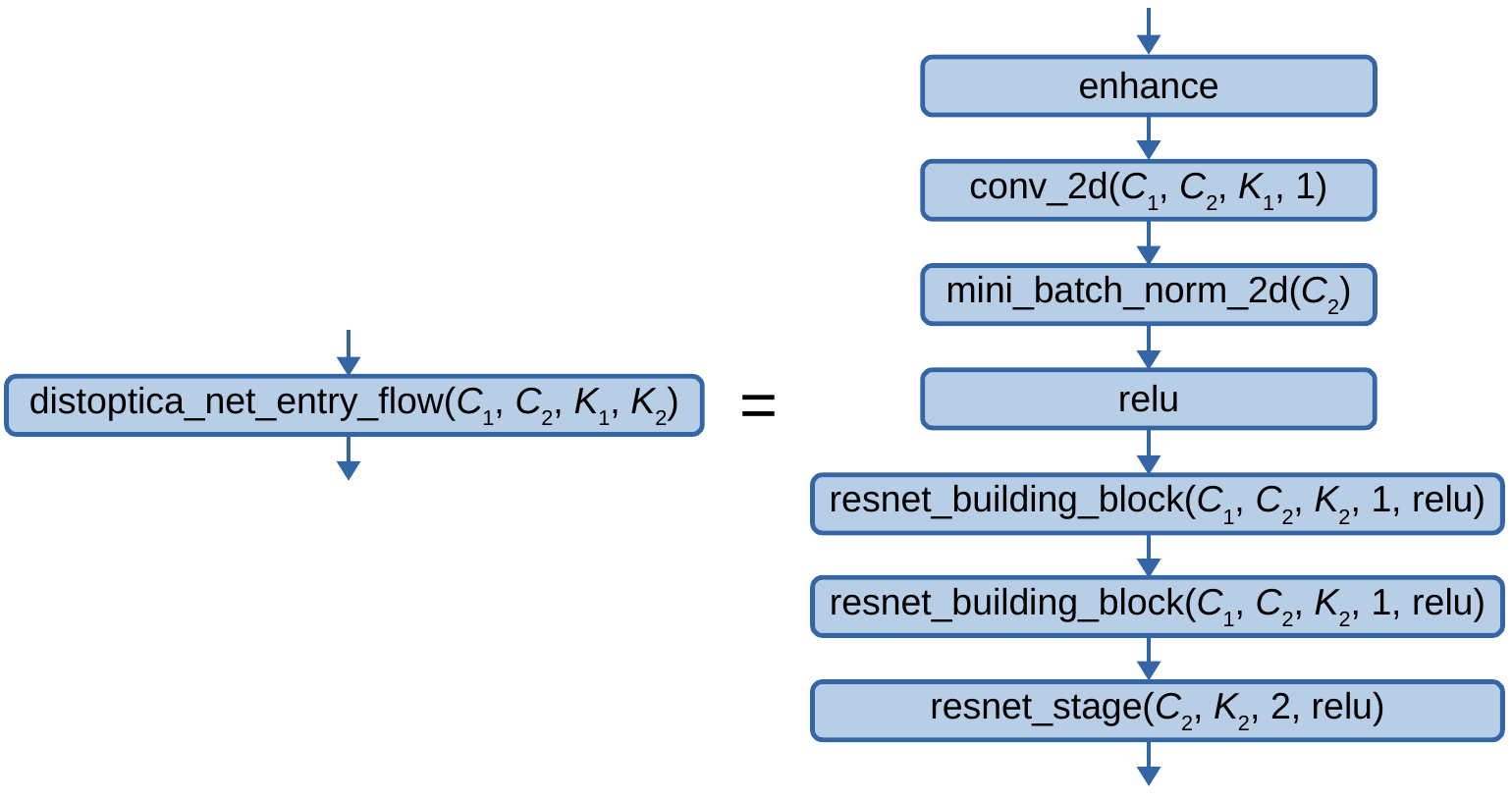
Fig. 2.1.1.1.1.14.4 The DistopticaNet entry flow, where \(C_1\), \(C_2\), \(K_1\), and \(K_2\) are the number of input channels, the number of output channels, the kernel size of the first convolutional layer, and the maximum kernel size of the resnet building blocks respectively.
Next, we introduce the DistopticaNet middle flow, defined graphically as:
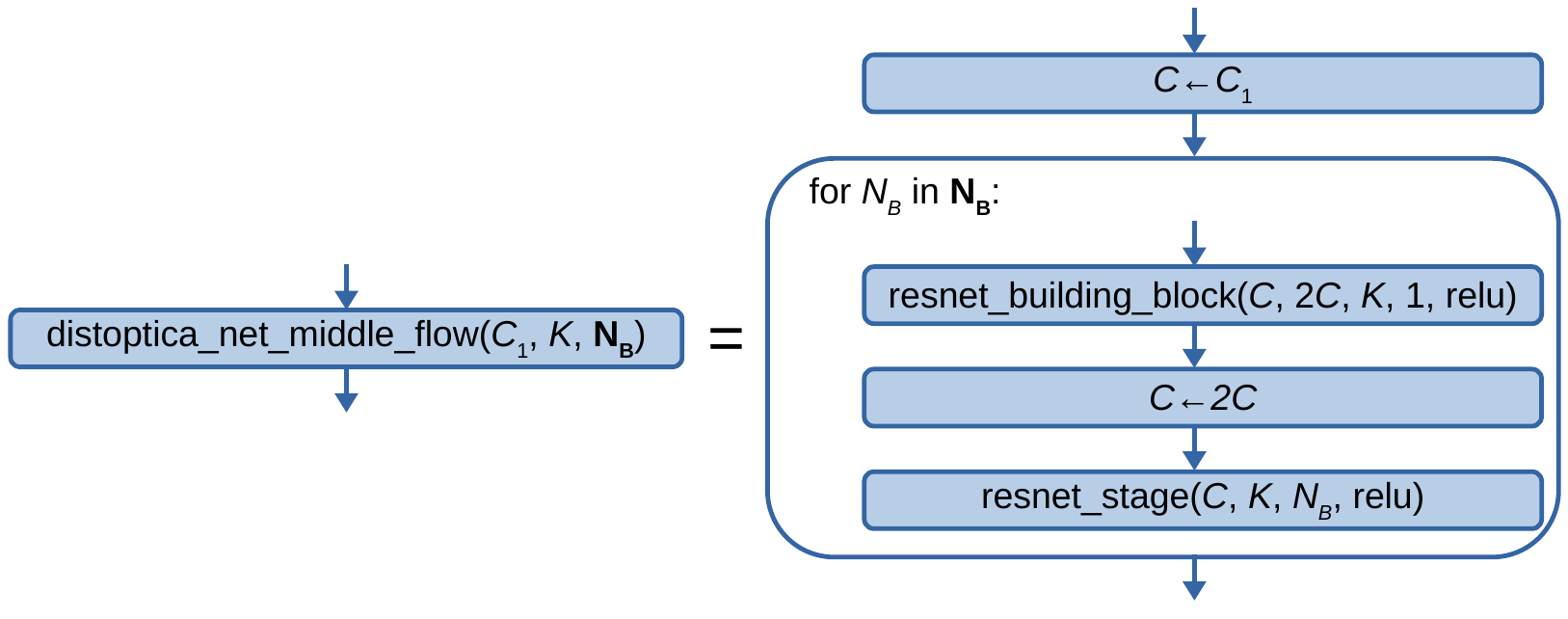
Fig. 2.1.1.1.1.14.5 The DistopticaNet middle flow, where \(C_1\), \(K\), and \(\mathbf{N}_{\mathbf{B}}\) are the number of input channels, the maximum kernel size, and the building block counts in the residual network stages of the middle flow respectively.
The above image introduces the block of the general form \(X \leftarrow Y\), which denotes the operation of setting the variable \(X\) to the value of \(Y\) while leaving the input tensor of said block unchanged.
Next, we introduce the DistopticaNet exit flow, defined graphically as:
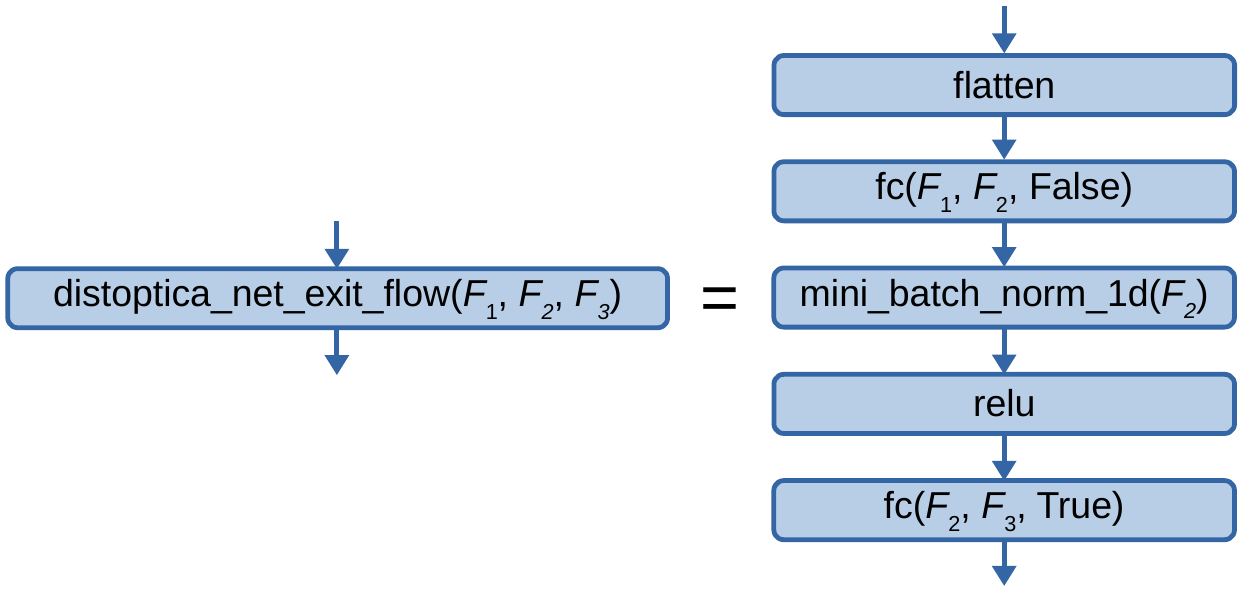
Fig. 2.1.1.1.1.14.6 The no-pool DistopticaNet exit flow, where \(F_1\), \(F_2\), and \(F_3\) are the number of nodes in the third last, the second last, and the last layers respectively.
The above image introduces several mathematical objects: \(\text{flatten}\) is the flatten operation applied to all but the ML data instance dimension; \(\text{fc}\left(F_{1},F_{2},\text{biases}\right)\) is a fully-connected layer with \(F_1\) input channels, \(F_2\) output channels, and the biases fixed to zero if the boolean variable \(\text{biases}\) is set to \(\text{False}\); \(\text{mini_batch_norm_1d}\left(C\right)\) is a mini-batch normalization layer of 1D inputs with \(C\) input channels.
Finally, the DistopticaNet architecture is defined graphically as:
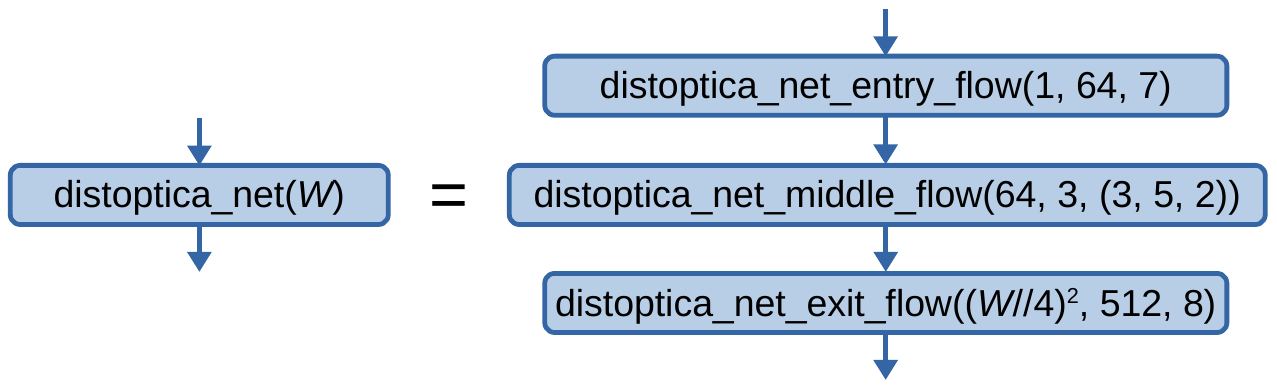
Fig. 2.1.1.1.1.14.7 The
"distoptica_net"architecture, where \(W\) is the width of the input tensor in pixels.See the documentation for the method
emicroml.modelling.cbed.distortion.estimation.MLModel.forward()for a discussion on how the output tensor is parsed as a dictionary.The weights of all the convolutional and fully-connected (FC) layers, except for those of the last FC layer, are He-initialized using the function
torch.nn.init.kaiming_normal_(), with the parametersa,mode,nonlinearity, andgeneratorset to0,'fan_out','relu', andNonerespectively. The weights of the last FC layer are Glorot-initialized using the functiontorch.nn.init.xavier_normal_(), with the parametersgain, andgeneratorset to5/3andNonerespectively.The biases of the last FC layer, and all of the mini-batch normalization layers are initialized to zero; the weights of all the mini-batch normalization layers except for those of the mini-batch normalization layers in \(\text{shortcut}\left(C_{1},C_{2},N_{\downarrow}\right)\) objects are normalized to unity; and the weights of the mini-batch normalization layers in \(\text{shortcut}\left(C_{1},C_{2},N_{\downarrow}\right)\) objects are normalized to zero.
- mini_batch_norm_epsfloat, optional
This parameter specifies the value to use for the construction parameter
epsfor every construction of an instance of the classtorch.nn.BatchNorm1dand every construction of an instance of the classtorch.nn.BatchNorm2d. Must be a positive number.- normalization_weightsdict, optional
The normalization weights of the ML dataset used or to be used to train the ML model. This parameter is expected to be equal to the instance attribute
emicroml.modelling.cbed.distortion.estimation.MLDataset.normalization_weightsof the instance of the classemicroml.modelling.cbed.distortion.estimation.MLDatasetrepresenting the aforementioned ML dataset. See the documentation for the functionemicroml.modelling.cbed.distortion.estimation.normalize_normalizable_elems_in_ml_data_dict()for a discussion on normalizing features of ML data instances.- normalization_biasesdict, optional
The normalization biases of the ML dataset used or to be used to train the ML model. This parameter is expected to be equal to the instance attribute
emicroml.modelling.cbed.distortion.estimation.MLDataset.normalization_biasesof the instance of the classemicroml.modelling.cbed.distortion.estimation.MLDatasetrepresenting the aforementioned ML dataset.
- Attributes:
core_attrsdict: The “core attributes”, i.e. the construction parameters.
Methods
add_module(name, module)Add a child module to the current module.
apply(fn)Apply
fnrecursively to every submodule (as returned by.children()) as well as self.bfloat16()Casts all floating point parameters and buffers to
bfloat16datatype.buffers([recurse])Return an iterator over module buffers.
children()Return an iterator over immediate children modules.
compile(*args, **kwargs)Compile this Module's forward using
torch.compile().cpu()Move all model parameters and buffers to the CPU.
cuda([device])Move all model parameters and buffers to the GPU.
double()Casts all floating point parameters and buffers to
doubledatatype.eval()Set the module in evaluation mode.
Return the extra representation of the module.
float()Casts all floating point parameters and buffers to
floatdatatype.forward(ml_inputs)Perform forward propagation.
get_buffer(target)Return the buffer given by
targetif it exists, otherwise throw an error.get_core_attrs([deep_copy])Return the "core attributes", i.e. the construction parameters, as a dict object.
Return any extra state to include in the module's state_dict.
get_parameter(target)Return the parameter given by
targetif it exists, otherwise throw an error.get_submodule(target)Return the submodule given by
targetif it exists, otherwise throw an error.half()Casts all floating point parameters and buffers to
halfdatatype.ipu([device])Move all model parameters and buffers to the IPU.
load_state_dict(state_dict[, strict, assign])Copy parameters and buffers from
state_dictinto this module and its descendants.make_predictions(ml_inputs[, ...])Make predictions according to machine learning inputs.
modules()Return an iterator over all modules in the network.
mtia([device])Move all model parameters and buffers to the MTIA.
named_buffers([prefix, recurse, ...])Return an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.
Return an iterator over immediate children modules, yielding both the name of the module as well as the module itself.
named_modules([memo, prefix, remove_duplicate])Return an iterator over all modules in the network, yielding both the name of the module as well as the module itself.
named_parameters([prefix, recurse, ...])Return an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.
parameters([recurse])Return an iterator over module parameters.
predict_distortion_models(cbed_pattern_images)Predict distortion models according to a mini-batch of images.
register_backward_hook(hook)Register a backward hook on the module.
register_buffer(name, tensor[, persistent])Add a buffer to the module.
register_forward_hook(hook, *[, prepend, ...])Register a forward hook on the module.
register_forward_pre_hook(hook, *[, ...])Register a forward pre-hook on the module.
register_full_backward_hook(hook[, prepend])Register a backward hook on the module.
register_full_backward_pre_hook(hook[, prepend])Register a backward pre-hook on the module.
Register a post-hook to be run after module's
load_state_dict()is called.Register a pre-hook to be run before module's
load_state_dict()is called.register_module(name, module)Alias for
add_module().register_parameter(name, param)Add a parameter to the module.
Register a post-hook for the
state_dict()method.Register a pre-hook for the
state_dict()method.requires_grad_([requires_grad])Change if autograd should record operations on parameters in this module.
set_extra_state(state)Set extra state contained in the loaded state_dict.
set_submodule(target, module[, strict])Set the submodule given by
targetif it exists, otherwise throw an error.state_dict(*args[, destination, prefix, ...])Return a dictionary containing references to the whole state of the module.
to(*args, **kwargs)Move and/or cast the parameters and buffers.
to_empty(*, device[, recurse])Move the parameters and buffers to the specified device without copying storage.
train([mode])Set the module in training mode.
type(dst_type)Casts all parameters and buffers to
dst_type.xpu([device])Move all model parameters and buffers to the XPU.
zero_grad([set_to_none])Reset gradients of all model parameters.
__call__
Initialize internal Module state, shared by both nn.Module and ScriptModule.
- Attributes:
core_attrsdict: The “core attributes”, i.e. the construction parameters.
Methods
add_module(name, module)Add a child module to the current module.
apply(fn)Apply
fnrecursively to every submodule (as returned by.children()) as well as self.bfloat16()Casts all floating point parameters and buffers to
bfloat16datatype.buffers([recurse])Return an iterator over module buffers.
children()Return an iterator over immediate children modules.
compile(*args, **kwargs)Compile this Module's forward using
torch.compile().cpu()Move all model parameters and buffers to the CPU.
cuda([device])Move all model parameters and buffers to the GPU.
double()Casts all floating point parameters and buffers to
doubledatatype.eval()Set the module in evaluation mode.
Return the extra representation of the module.
float()Casts all floating point parameters and buffers to
floatdatatype.forward(ml_inputs)Perform forward propagation.
get_buffer(target)Return the buffer given by
targetif it exists, otherwise throw an error.get_core_attrs([deep_copy])Return the "core attributes", i.e. the construction parameters, as a dict object.
Return any extra state to include in the module's state_dict.
get_parameter(target)Return the parameter given by
targetif it exists, otherwise throw an error.get_submodule(target)Return the submodule given by
targetif it exists, otherwise throw an error.half()Casts all floating point parameters and buffers to
halfdatatype.ipu([device])Move all model parameters and buffers to the IPU.
load_state_dict(state_dict[, strict, assign])Copy parameters and buffers from
state_dictinto this module and its descendants.make_predictions(ml_inputs[, ...])Make predictions according to machine learning inputs.
modules()Return an iterator over all modules in the network.
mtia([device])Move all model parameters and buffers to the MTIA.
named_buffers([prefix, recurse, ...])Return an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.
Return an iterator over immediate children modules, yielding both the name of the module as well as the module itself.
named_modules([memo, prefix, remove_duplicate])Return an iterator over all modules in the network, yielding both the name of the module as well as the module itself.
named_parameters([prefix, recurse, ...])Return an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.
parameters([recurse])Return an iterator over module parameters.
predict_distortion_models(cbed_pattern_images)Predict distortion models according to a mini-batch of images.
register_backward_hook(hook)Register a backward hook on the module.
register_buffer(name, tensor[, persistent])Add a buffer to the module.
register_forward_hook(hook, *[, prepend, ...])Register a forward hook on the module.
register_forward_pre_hook(hook, *[, ...])Register a forward pre-hook on the module.
register_full_backward_hook(hook[, prepend])Register a backward hook on the module.
register_full_backward_pre_hook(hook[, prepend])Register a backward pre-hook on the module.
Register a post-hook to be run after module's
load_state_dict()is called.Register a pre-hook to be run before module's
load_state_dict()is called.register_module(name, module)Alias for
add_module().register_parameter(name, param)Add a parameter to the module.
Register a post-hook for the
state_dict()method.Register a pre-hook for the
state_dict()method.requires_grad_([requires_grad])Change if autograd should record operations on parameters in this module.
set_extra_state(state)Set extra state contained in the loaded state_dict.
set_submodule(target, module[, strict])Set the submodule given by
targetif it exists, otherwise throw an error.state_dict(*args[, destination, prefix, ...])Return a dictionary containing references to the whole state of the module.
to(*args, **kwargs)Move and/or cast the parameters and buffers.
to_empty(*, device[, recurse])Move the parameters and buffers to the specified device without copying storage.
train([mode])Set the module in training mode.
type(dst_type)Casts all parameters and buffers to
dst_type.xpu([device])Move all model parameters and buffers to the XPU.
zero_grad([set_to_none])Reset gradients of all model parameters.
__call__
Methods
Add a child module to the current module.
Apply
fnrecursively to every submodule (as returned by.children()) as well as self.Casts all floating point parameters and buffers to
bfloat16datatype.Return an iterator over module buffers.
Return an iterator over immediate children modules.
Compile this Module's forward using
torch.compile().Move all model parameters and buffers to the CPU.
Move all model parameters and buffers to the GPU.
Casts all floating point parameters and buffers to
doubledatatype.Set the module in evaluation mode.
Return the extra representation of the module.
Casts all floating point parameters and buffers to
floatdatatype.Perform forward propagation.
Return the buffer given by
targetif it exists, otherwise throw an error.Return the "core attributes", i.e. the construction parameters, as a dict object.
Return any extra state to include in the module's state_dict.
Return the parameter given by
targetif it exists, otherwise throw an error.Return the submodule given by
targetif it exists, otherwise throw an error.Casts all floating point parameters and buffers to
halfdatatype.Move all model parameters and buffers to the IPU.
Copy parameters and buffers from
state_dictinto this module and its descendants.Make predictions according to machine learning inputs.
Return an iterator over all modules in the network.
Move all model parameters and buffers to the MTIA.
Return an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.
Return an iterator over immediate children modules, yielding both the name of the module as well as the module itself.
Return an iterator over all modules in the network, yielding both the name of the module as well as the module itself.
Return an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.
Return an iterator over module parameters.
Predict distortion models according to a mini-batch of images.
Register a backward hook on the module.
Add a buffer to the module.
Register a forward hook on the module.
Register a forward pre-hook on the module.
Register a backward hook on the module.
Register a backward pre-hook on the module.
Register a post-hook to be run after module's
load_state_dict()is called.Register a pre-hook to be run before module's
load_state_dict()is called.Alias for
add_module().Add a parameter to the module.
Register a post-hook for the
state_dict()method.Register a pre-hook for the
state_dict()method.Change if autograd should record operations on parameters in this module.
Set extra state contained in the loaded state_dict.
Set the submodule given by
targetif it exists, otherwise throw an error.Return a dictionary containing references to the whole state of the module.
Move and/or cast the parameters and buffers.
Move the parameters and buffers to the specified device without copying storage.
Set the module in training mode.
Casts all parameters and buffers to
dst_type.Move all model parameters and buffers to the XPU.
Reset gradients of all model parameters.
Attributes
T_destinationcall_super_initdict: The "core attributes", i.e. the construction parameters.
dump_patchestraining- __call__(*args, **kwargs)
Call self as a function.
- add_module(name, module)
Add a child module to the current module.
The module can be accessed as an attribute using the given name.
- Return type:
- Args:
- name (str): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
- apply(fn)
Apply
fnrecursively to every submodule (as returned by.children()) as well as self.Typical use includes initializing the parameters of a model (see also torch.nn.init).
- Return type:
Self
- Args:
fn (
Module-> None): function to be applied to each submodule- Returns:
Module: self
Example:
>>> @torch.no_grad() >>> def init_weights(m): >>> print(m) >>> if type(m) is nn.Linear: >>> m.weight.fill_(1.0) >>> print(m.weight) >>> net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) >>> net.apply(init_weights) Linear(in_features=2, out_features=2, bias=True) Parameter containing: tensor([[1., 1.], [1., 1.]], requires_grad=True) Linear(in_features=2, out_features=2, bias=True) Parameter containing: tensor([[1., 1.], [1., 1.]], requires_grad=True) Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) )
- bfloat16()
Casts all floating point parameters and buffers to
bfloat16datatype. :rtype:SelfNote
This method modifies the module in-place.
- Returns:
Module: self
- buffers(recurse=True)
Return an iterator over module buffers.
- Args:
- recurse (bool): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that are direct members of this module.
- Yields:
torch.Tensor: module buffer
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> for buf in model.buffers(): >>> print(type(buf), buf.size()) <class 'torch.Tensor'> (20L,) <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
- children()
Return an iterator over immediate children modules.
- Yields:
Module: a child module
- compile(*args, **kwargs)
Compile this Module’s forward using
torch.compile().This Module’s __call__ method is compiled and all arguments are passed as-is to
torch.compile().See
torch.compile()for details on the arguments for this function.- Return type:
- property core_attrs
dict: The “core attributes”, i.e. the construction parameters.
Note that
core_attrsshould be considered read-only.
- cpu()
Move all model parameters and buffers to the CPU. :rtype:
SelfNote
This method modifies the module in-place.
- Returns:
Module: self
- cuda(device=None)
Move all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So it should be called before constructing the optimizer if the module will live on GPU while being optimized. :rtype:
SelfNote
This method modifies the module in-place.
- Args:
- device (int, optional): if specified, all parameters will be
copied to that device
- Returns:
Module: self
- double()
Casts all floating point parameters and buffers to
doubledatatype. :rtype:SelfNote
This method modifies the module in-place.
- Returns:
Module: self
- eval()
Set the module in evaluation mode.
This has an effect only on certain modules. See the documentation of particular modules for details of their behaviors in training/evaluation mode, i.e. whether they are affected, e.g.
Dropout,BatchNorm, etc.This is equivalent with
self.train(False).See Locally disabling gradient computation for a comparison between .eval() and several similar mechanisms that may be confused with it.
- Return type:
Self
- Returns:
Module: self
- extra_repr()
Return the extra representation of the module.
To print customized extra information, you should re-implement this method in your own modules. Both single-line and multi-line strings are acceptable.
- Return type:
- float()
Casts all floating point parameters and buffers to
floatdatatype. :rtype:SelfNote
This method modifies the module in-place.
- Returns:
Module: self
- forward(ml_inputs)[source]
Perform forward propagation.
The current function forward propagates a dictionary representation
ml_inputsof a mini-batch of machine learning (ML) inputs through the ML model.The ML model takes as input a mini-batch of images, where each image is assumed to depict a distorted CBED pattern, and as output, the ML model predicts sets of coordinate transformation parameters that specify the coordinate transformations that describe the distortions of the input images. The coordinate transformation used to describe the distortions of an image is defined in the documentation for the class
distoptica.StandardCoordTransformParams. The parameter set parameterizing said coordinate transformation is referred to as the “standard” coordinate transformation parameter set, and is represented by the classdistoptica.StandardCoordTransformParams. See the documentation for said class for a discussion on standard coordinate transformation parameter sets.The output tensor
output_tensorof the neural network of the ML model is an 8-column PyTorch tensor, i.e. PyTorch matrix, of the data typetorch.float32. Letmini_batch_sizebe the number of rows in theoutput_tensor. For each nonnegative integernless thanmini_batch_size,output_tensor[n]stores the predicted normalized parameters of the standard coordinate transformation that are suppose to describe the distortions of thenth input image of the mini-batch. The parameters are normalized according to the normalization weights and biases of the ML dataset used or to be used to train the ML model. See the documentation for the functionemicroml.modelling.cbed.distortion.estimation.normalize_normalizable_elems_in_ml_data_dict()for a discussion on normalizing features of ML data instances, e.g. the standard coordinate transformation parameters. The normalization weights and biases are stored incore_attrs["normalization_weights"]andcore_attrs["normalization_biases"]respectively, wherecore_attrsis the instance attributeemicroml.modelling.cbed.distortion.estimation.MLModel.core_attrs.output_tensor[:, 0]stores the normalized quadratic radial distortion amplitudes,output_tensor[:, 1]stores the normalized spiral distortion amplitudes,output_tensor[:, 2:4]stores the normalized elliptical distortion vectors,output_tensor[:, 4:6]stores the normalized parabolic distortion vectors, andoutput_tensor[:, 6:8]stores the normalized distortion centers.- Parameters:
- ml_inputsdict
The dictionary representation of the mini-batch of ML inputs.
ml_inputsmust have only one dict key, the value of which being"cbed_pattern_images".ml_inputs["cbed_pattern_images"]must be a 3D PyTorch tensor of the data typetorch.float32storing the mini-batch of images assumed to depict distorted CBED patterns. For each nonnegative integernless thanmini_batch_size,ml_inputs["cbed_pattern_images"][n]stores thenth input image of the mini-batch.mini_batch_sizemust be positive andml_inputs["cbed_pattern_images"].shape[1:]must be equal to2*(num_pixels_across_each_cbed_pattern,), wherenum_pixels_across_each_cbed_patterniscore_attrs["num_pixels_across_each_cbed_pattern"], i.e. the number of pixels across each input image.
- Returns:
- ml_predictionsdict
The dictionary representation of the mini-batch of ML outputs.
Using the output tensor
output_tensordiscussed above,ml_predictionsis constructed essentially byml_predictions = {"quadratic_radial_distortion_amplitudes": \ output_tensor[:, 0], "spiral_distortion_amplitudes": \ output_tensor[:, 1], "elliptical_distortion_vectors": \ output_tensor[:, 2:4], "parabolic_distortion_vectors": \ output_tensor[:, 4:6], "distortion_centers": \ output_tensor[:, 6:8]}
Users can use the function
emicroml.modelling.cbed.distortion.estimation.ml_data_dict_to_distortion_models()to convertml_predictionsto a sequence of distortion models, with each distortion model being represented by the classdistoptica.DistortionModel.
- get_buffer(target)
Return the buffer given by
targetif it exists, otherwise throw an error.See the docstring for
get_submodulefor a more detailed explanation of this method’s functionality as well as how to correctly specifytarget.- Return type:
- Args:
- target: The fully-qualified string name of the buffer
to look for. (See
get_submodulefor how to specify a fully-qualified string.)
- Returns:
torch.Tensor: The buffer referenced by
target- Raises:
- AttributeError: If the target string references an invalid
path or resolves to something that is not a buffer
- get_core_attrs(deep_copy=True)
Return the “core attributes”, i.e. the construction parameters, as a dict object.
- Parameters:
- deep_copybool, optional
Let
core_attrsdenote the core attributes.If
deep_copyis set toTrue, then a deep copy ofcore_attrsis returned. Otherwise, a shallow copy ofcore_attrsis returned.
- Returns:
- core_attrsdict
The core attributes.
- get_extra_state()
Return any extra state to include in the module’s state_dict.
Implement this and a corresponding
set_extra_state()for your module if you need to store extra state. This function is called when building the module’s state_dict().Note that extra state should be picklable to ensure working serialization of the state_dict. We only provide backwards compatibility guarantees for serializing Tensors; other objects may break backwards compatibility if their serialized pickled form changes.
- Return type:
- Returns:
object: Any extra state to store in the module’s state_dict
- get_parameter(target)
Return the parameter given by
targetif it exists, otherwise throw an error.See the docstring for
get_submodulefor a more detailed explanation of this method’s functionality as well as how to correctly specifytarget.- Return type:
- Args:
- target: The fully-qualified string name of the Parameter
to look for. (See
get_submodulefor how to specify a fully-qualified string.)
- Returns:
torch.nn.Parameter: The Parameter referenced by
target- Raises:
- AttributeError: If the target string references an invalid
path or resolves to something that is not an
nn.Parameter
- get_submodule(target)
Return the submodule given by
targetif it exists, otherwise throw an error.For example, let’s say you have an
nn.ModuleAthat looks like this:A( (net_b): Module( (net_c): Module( (conv): Conv2d(16, 33, kernel_size=(3, 3), stride=(2, 2)) ) (linear): Linear(in_features=100, out_features=200, bias=True) ) )(The diagram shows an
nn.ModuleA.Awhich has a nested submodulenet_b, which itself has two submodulesnet_candlinear.net_cthen has a submoduleconv.)To check whether or not we have the
linearsubmodule, we would callget_submodule("net_b.linear"). To check whether we have theconvsubmodule, we would callget_submodule("net_b.net_c.conv").The runtime of
get_submoduleis bounded by the degree of module nesting intarget. A query againstnamed_modulesachieves the same result, but it is O(N) in the number of transitive modules. So, for a simple check to see if some submodule exists,get_submoduleshould always be used.- Return type:
- Args:
- target: The fully-qualified string name of the submodule
to look for. (See above example for how to specify a fully-qualified string.)
- Returns:
torch.nn.Module: The submodule referenced by
target- Raises:
- AttributeError: If at any point along the path resulting from
the target string the (sub)path resolves to a non-existent attribute name or an object that is not an instance of
nn.Module.
- half()
Casts all floating point parameters and buffers to
halfdatatype. :rtype:SelfNote
This method modifies the module in-place.
- Returns:
Module: self
- ipu(device=None)
Move all model parameters and buffers to the IPU.
This also makes associated parameters and buffers different objects. So it should be called before constructing the optimizer if the module will live on IPU while being optimized. :rtype:
SelfNote
This method modifies the module in-place.
- Arguments:
- device (int, optional): if specified, all parameters will be
copied to that device
- Returns:
Module: self
- load_state_dict(state_dict, strict=True, assign=False)
Copy parameters and buffers from
state_dictinto this module and its descendants.If
strictisTrue, then the keys ofstate_dictmust exactly match the keys returned by this module’sstate_dict()function.Warning
If
assignisTruethe optimizer must be created after the call toload_state_dictunlessget_swap_module_params_on_conversion()isTrue.- Args:
- state_dict (dict): a dict containing parameters and
persistent buffers.
- strict (bool, optional): whether to strictly enforce that the keys
in
state_dictmatch the keys returned by this module’sstate_dict()function. Default:True- assign (bool, optional): When set to
False, the properties of the tensors in the current module are preserved whereas setting it to
Truepreserves properties of the Tensors in the state dict. The only exception is therequires_gradfield ofParameterfor which the value from the module is preserved. Default:False
- Returns:
NamedTuplewithmissing_keysandunexpected_keysfields:missing_keysis a list of str containing any keys that are expectedby this module but missing from the provided
state_dict.
unexpected_keysis a list of str containing the keys that are notexpected by this module but present in the provided
state_dict.
- Note:
If a parameter or buffer is registered as
Noneand its corresponding key exists instate_dict,load_state_dict()will raise aRuntimeError.
- make_predictions(ml_inputs, unnormalize_normalizable_elems_of_ml_predictions=False)[source]
Make predictions according to machine learning inputs.
The machine learning (ML) model takes as input a mini-batch of images, where each image is assumed to depict a distorted CBED pattern, and as output, the ML model predicts sets of coordinate transformation parameters that specify the coordinate transformations that describe the distortions of the input images. The coordinate transformation used to describe the distortions of an image is defined in the documentation for the class
distoptica.StandardCoordTransformParams. The parameter set parameterizing said coordinate transformation is referred to as the “standard” coordinate transformation parameter set, and is represented by the classdistoptica.StandardCoordTransformParams. See the documentation for said class for a discussion on standard coordinate transformation parameter sets.- Parameters:
- ml_inputsdict
The dictionary representation of the mini-batch of ML inputs.
ml_inputsmust have the dict key"cbed_pattern_images".ml_inputs["cbed_pattern_images"]must be a 3D PyTorch tensor of the data typetorch.float32storing the mini-batch of images assumed to depict distorted CBED patterns. Letmini_batch_sizebeml_inputs["cbed_pattern_images"].shape[0], andcore_attrsbe the instance attributeemicroml.modelling.cbed.distortion.estimation.MLModel.core_attrs. For each nonnegative integernless thanmini_batch_size,ml_inputs["cbed_pattern_images"][n]stores thenth input image of the mini-batch.mini_batch_sizemust be positive andml_inputs["cbed_pattern_images"].shape[1:]must be equal to2*(num_pixels_across_each_cbed_pattern,), wherenum_pixels_across_each_cbed_patterniscore_attrs["num_pixels_across_each_cbed_pattern"], i.e. the number of pixels across each input image.- unnormalize_normalizable_elems_of_ml_predictionsbool
If
unnormalize_normalizable_elems_of_ml_predictionsis set toFalse, then the predicted parameters of the standard coordinate transformations are returned normalized. Otherwise, said parameters are returned unnormalized. See the description below ofml_predictionsfor more details on how this is implemented effectively.
- Returns:
- ml_predictionsdict
The dictionary representation of the mini-batch of ML outputs.
Let
ml_modelbe an instance of the current class. Thenml_predictionsis calculated effectively by:import emicroml.modelling.cbed.distortion.estimation module_alias = \ emicroml.modelling.cbed.distortion.estimation func_alias = \ module_alias.unnormalize_normalizable_elems_in_ml_data_dict ml_predictions = ml_model.forward(ml_inputs) if unnormalize_normalizable_elems_of_ml_predictions: kwargs = {"ml_data_dict": \ ml_predictions, "normalization_weights": \ ml_model.core_attrs["normalization_weights"], "normalization_biases": \ ml_model.core_attrs["normalization_biases"]} ml_predictions = func_alias(**kwargs)
See the documentation for the method
emicroml.modelling.cbed.distortion.estimation.MLModel.forward()for details on the output returned by said method. See the documentation for the functionemicroml.modelling.cbed.distortion.estimation.normalize_normalizable_elems_in_ml_data_dict()for a discussion on normalizing features of ML data instances, e.g. the standard coordinate transformation parameters.Users can use the function
emicroml.modelling.cbed.distortion.estimation.ml_data_dict_to_distortion_models()to convertml_predictionsto a sequence of distortion models, with each distortion model being represented by the classdistoptica.DistortionModel.
- modules()
Return an iterator over all modules in the network.
- Yields:
Module: a module in the network
- Note:
Duplicate modules are returned only once. In the following example,
lwill be returned only once.
Example:
>>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) >>> for idx, m in enumerate(net.modules()): ... print(idx, '->', m) 0 -> Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) ) 1 -> Linear(in_features=2, out_features=2, bias=True)
- mtia(device=None)
Move all model parameters and buffers to the MTIA.
This also makes associated parameters and buffers different objects. So it should be called before constructing the optimizer if the module will live on MTIA while being optimized. :rtype:
SelfNote
This method modifies the module in-place.
- Arguments:
- device (int, optional): if specified, all parameters will be
copied to that device
- Returns:
Module: self
- named_buffers(prefix='', recurse=True, remove_duplicate=True)
Return an iterator over module buffers, yielding both the name of the buffer as well as the buffer itself.
- Args:
prefix (str): prefix to prepend to all buffer names. recurse (bool, optional): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that are direct members of this module. Defaults to True.
remove_duplicate (bool, optional): whether to remove the duplicated buffers in the result. Defaults to True.
- Yields:
(str, torch.Tensor): Tuple containing the name and buffer
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> for name, buf in self.named_buffers(): >>> if name in ['running_var']: >>> print(buf.size())
- named_children()
Return an iterator over immediate children modules, yielding both the name of the module as well as the module itself.
- Yields:
(str, Module): Tuple containing a name and child module
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> for name, module in model.named_children(): >>> if name in ['conv4', 'conv5']: >>> print(module)
- named_modules(memo=None, prefix='', remove_duplicate=True)
Return an iterator over all modules in the network, yielding both the name of the module as well as the module itself.
- Args:
memo: a memo to store the set of modules already added to the result prefix: a prefix that will be added to the name of the module remove_duplicate: whether to remove the duplicated module instances in the result
or not
- Yields:
(str, Module): Tuple of name and module
- Note:
Duplicate modules are returned only once. In the following example,
lwill be returned only once.
Example:
>>> l = nn.Linear(2, 2) >>> net = nn.Sequential(l, l) >>> for idx, m in enumerate(net.named_modules()): ... print(idx, '->', m) 0 -> ('', Sequential( (0): Linear(in_features=2, out_features=2, bias=True) (1): Linear(in_features=2, out_features=2, bias=True) )) 1 -> ('0', Linear(in_features=2, out_features=2, bias=True))
- named_parameters(prefix='', recurse=True, remove_duplicate=True)
Return an iterator over module parameters, yielding both the name of the parameter as well as the parameter itself.
- Args:
prefix (str): prefix to prepend to all parameter names. recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that are direct members of this module.
- remove_duplicate (bool, optional): whether to remove the duplicated
parameters in the result. Defaults to True.
- Yields:
(str, Parameter): Tuple containing the name and parameter
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> for name, param in self.named_parameters(): >>> if name in ['bias']: >>> print(param.size())
- parameters(recurse=True)
Return an iterator over module parameters.
This is typically passed to an optimizer.
- Args:
- recurse (bool): if True, then yields parameters of this module
and all submodules. Otherwise, yields only parameters that are direct members of this module.
- Yields:
Parameter: module parameter
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> for param in model.parameters(): >>> print(type(param), param.size()) <class 'torch.Tensor'> (20L,) <class 'torch.Tensor'> (20L, 1L, 5L, 5L)
- predict_distortion_models(cbed_pattern_images, sampling_grid_dims_in_pixels=(512, 512), least_squares_alg_params=None)[source]
Predict distortion models according to a mini-batch of images.
The machine learning (ML) model takes as input a mini-batch of images, where each image is assumed to depict a distorted CBED pattern, and as output, the ML model predicts a set of distortion models that describe the distortions of the input images. The distortion model used to describe the distortion of an image is defined in the documentation for the class
distoptica.DistortionModel. See the documentation for the classdistoptica.DistortionModelfor a discussion on distortion models.For each CBED pattern image, an instance
distortion_modelof the classdistoptica.DistortionModelis constructed according to the distortions predicted by the ML model.- Parameters:
- cbed_pattern_imagesarray_like (float, ndim=3)
The mini-batch of images. Let
mini_batch_sizebecbed_pattern_images.shape[0], andcore_attrsbe the instance attributeemicroml.modelling.cbed.distortion.estimation.MLModel.core_attrs. For each nonnegative integernless thanmini_batch_size,cbed_pattern_images[n]stores thenth input image of the mini-batch.mini_batch_sizemust be positive andcbed_pattern_images.shape[1:]must be equal to2*(num_pixels_across_each_cbed_pattern,), wherenum_pixels_across_each_cbed_patterniscore_attrs["num_pixels_across_each_cbed_pattern"], i.e. the number of pixels across each input image.- sampling_grid_dims_in_pixelsarray_like (int, shape=(2,)), optional
The dimensions of the sampling grid, in units of pixels, used for all distortion models.
- least_squares_alg_params
distoptica.LeastSquaresAlgParams| None, optional least_squares_alg_paramsspecifies the parameters of the least-squares algorithm to be used to calculate the mappings of fractional Cartesian coordinates of distorted images to those of the corresponding undistorted images.least_squares_alg_paramsis used to calculate the distortion models mentioned above in the summary documentation. Ifleast_squares_alg_paramsis set toNone, then the parameter will be reassigned to the valuedistoptica.LeastSquaresAlgParams(). See the documentation for the classdistoptica.LeastSquaresAlgParamsfor details on the parameters of the least-squares algorithm.
- Returns:
- distortion_modelsarray_like (
distoptica.DistortionModel, ndim=1) The distortion models. Note that each distortion model is stored on the same device as that on which the ML model is stored.
- distortion_modelsarray_like (
- register_backward_hook(hook)
Register a backward hook on the module.
This function is deprecated in favor of
register_full_backward_hook()and the behavior of this function will change in future versions.- Return type:
RemovableHandle
- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_buffer(name, tensor, persistent=True)
Add a buffer to the module.
This is typically used to register a buffer that should not be considered a model parameter. For example, BatchNorm’s
running_meanis not a parameter, but is part of the module’s state. Buffers, by default, are persistent and will be saved alongside parameters. This behavior can be changed by settingpersistenttoFalse. The only difference between a persistent buffer and a non-persistent buffer is that the latter will not be a part of this module’sstate_dict.Buffers can be accessed as attributes using given names.
- Return type:
- Args:
- name (str): name of the buffer. The buffer can be accessed
from this module using the given name
- tensor (Tensor or None): buffer to be registered. If
None, then operations that run on buffers, such as
cuda, are ignored. IfNone, the buffer is not included in the module’sstate_dict.- persistent (bool): whether the buffer is part of this module’s
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> self.register_buffer('running_mean', torch.zeros(num_features))
- register_forward_hook(hook, *, prepend=False, with_kwargs=False, always_call=False)
Register a forward hook on the module.
The hook will be called every time after
forward()has computed an output.If
with_kwargsisFalseor not specified, the input contains only the positional arguments given to the module. Keyword arguments won’t be passed to the hooks and only to theforward. The hook can modify the output. It can modify the input inplace but it will not have effect on forward since this is called afterforward()is called. The hook should have the following signature:hook(module, args, output) -> None or modified output
If
with_kwargsisTrue, the forward hook will be passed thekwargsgiven to the forward function and be expected to return the output possibly modified. The hook should have the following signature:hook(module, args, kwargs, output) -> None or modified output
- Return type:
RemovableHandle
- Args:
hook (Callable): The user defined hook to be registered. prepend (bool): If
True, the providedhookwill be firedbefore all existing
forwardhooks on thistorch.nn.Module. Otherwise, the providedhookwill be fired after all existingforwardhooks on thistorch.nn.Module. Note that globalforwardhooks registered withregister_module_forward_hook()will fire before all hooks registered by this method. Default:False- with_kwargs (bool): If
True, thehookwill be passed the kwargs given to the forward function. Default:
False- always_call (bool): If
Truethehookwill be run regardless of whether an exception is raised while calling the Module. Default:
False
- with_kwargs (bool): If
- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_forward_pre_hook(hook, *, prepend=False, with_kwargs=False)
Register a forward pre-hook on the module.
The hook will be called every time before
forward()is invoked.If
with_kwargsis false or not specified, the input contains only the positional arguments given to the module. Keyword arguments won’t be passed to the hooks and only to theforward. The hook can modify the input. User can either return a tuple or a single modified value in the hook. We will wrap the value into a tuple if a single value is returned (unless that value is already a tuple). The hook should have the following signature:hook(module, args) -> None or modified input
If
with_kwargsis true, the forward pre-hook will be passed the kwargs given to the forward function. And if the hook modifies the input, both the args and kwargs should be returned. The hook should have the following signature:hook(module, args, kwargs) -> None or a tuple of modified input and kwargs
- Return type:
RemovableHandle
- Args:
hook (Callable): The user defined hook to be registered. prepend (bool): If true, the provided
hookwill be fired beforeall existing
forward_prehooks on thistorch.nn.Module. Otherwise, the providedhookwill be fired after all existingforward_prehooks on thistorch.nn.Module. Note that globalforward_prehooks registered withregister_module_forward_pre_hook()will fire before all hooks registered by this method. Default:False- with_kwargs (bool): If true, the
hookwill be passed the kwargs given to the forward function. Default:
False
- with_kwargs (bool): If true, the
- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_full_backward_hook(hook, prepend=False)
Register a backward hook on the module.
The hook will be called every time the gradients with respect to a module are computed, and its firing rules are as follows: :rtype:
RemovableHandleOrdinarily, the hook fires when the gradients are computed with respect to the module inputs.
If none of the module inputs require gradients, the hook will fire when the gradients are computed with respect to module outputs.
If none of the module outputs require gradients, then the hooks will not fire.
The hook should have the following signature:
hook(module, grad_input, grad_output) -> tuple(Tensor) or None
The
grad_inputandgrad_outputare tuples that contain the gradients with respect to the inputs and outputs respectively. The hook should not modify its arguments, but it can optionally return a new gradient with respect to the input that will be used in place ofgrad_inputin subsequent computations.grad_inputwill only correspond to the inputs given as positional arguments and all kwarg arguments are ignored. Entries ingrad_inputandgrad_outputwill beNonefor all non-Tensor arguments.For technical reasons, when this hook is applied to a Module, its forward function will receive a view of each Tensor passed to the Module. Similarly the caller will receive a view of each Tensor returned by the Module’s forward function.
Warning
Modifying inputs or outputs inplace is not allowed when using backward hooks and will raise an error.
- Args:
hook (Callable): The user-defined hook to be registered. prepend (bool): If true, the provided
hookwill be fired beforeall existing
backwardhooks on thistorch.nn.Module. Otherwise, the providedhookwill be fired after all existingbackwardhooks on thistorch.nn.Module. Note that globalbackwardhooks registered withregister_module_full_backward_hook()will fire before all hooks registered by this method.- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_full_backward_pre_hook(hook, prepend=False)
Register a backward pre-hook on the module.
The hook will be called every time the gradients for the module are computed. The hook should have the following signature:
hook(module, grad_output) -> tuple[Tensor, ...], Tensor or None
The
grad_outputis a tuple. The hook should not modify its arguments, but it can optionally return a new gradient with respect to the output that will be used in place ofgrad_outputin subsequent computations. Entries ingrad_outputwill beNonefor all non-Tensor arguments.For technical reasons, when this hook is applied to a Module, its forward function will receive a view of each Tensor passed to the Module. Similarly the caller will receive a view of each Tensor returned by the Module’s forward function. :rtype:
RemovableHandleWarning
Modifying inputs inplace is not allowed when using backward hooks and will raise an error.
- Args:
hook (Callable): The user-defined hook to be registered. prepend (bool): If true, the provided
hookwill be fired beforeall existing
backward_prehooks on thistorch.nn.Module. Otherwise, the providedhookwill be fired after all existingbackward_prehooks on thistorch.nn.Module. Note that globalbackward_prehooks registered withregister_module_full_backward_pre_hook()will fire before all hooks registered by this method.- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_load_state_dict_post_hook(hook)
Register a post-hook to be run after module’s
load_state_dict()is called.- It should have the following signature::
hook(module, incompatible_keys) -> None
The
moduleargument is the current module that this hook is registered on, and theincompatible_keysargument is aNamedTupleconsisting of attributesmissing_keysandunexpected_keys.missing_keysis alistofstrcontaining the missing keys andunexpected_keysis alistofstrcontaining the unexpected keys.The given incompatible_keys can be modified inplace if needed.
Note that the checks performed when calling
load_state_dict()withstrict=Trueare affected by modifications the hook makes tomissing_keysorunexpected_keys, as expected. Additions to either set of keys will result in an error being thrown whenstrict=True, and clearing out both missing and unexpected keys will avoid an error.- Returns:
torch.utils.hooks.RemovableHandle:a handle that can be used to remove the added hook by calling
handle.remove()
- register_load_state_dict_pre_hook(hook)
Register a pre-hook to be run before module’s
load_state_dict()is called.- It should have the following signature::
hook(module, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs) -> None # noqa: B950
- Arguments:
- hook (Callable): Callable hook that will be invoked before
loading the state dict.
- register_module(name, module)
Alias for
add_module().- Return type:
- register_parameter(name, param)
Add a parameter to the module.
The parameter can be accessed as an attribute using given name.
- Return type:
- Args:
- name (str): name of the parameter. The parameter can be accessed
from this module using the given name
- param (Parameter or None): parameter to be added to the module. If
None, then operations that run on parameters, such ascuda, are ignored. IfNone, the parameter is not included in the module’sstate_dict.
- register_state_dict_post_hook(hook)
Register a post-hook for the
state_dict()method.- It should have the following signature::
hook(module, state_dict, prefix, local_metadata) -> None
The registered hooks can modify the
state_dictinplace.
- register_state_dict_pre_hook(hook)
Register a pre-hook for the
state_dict()method.- It should have the following signature::
hook(module, prefix, keep_vars) -> None
The registered hooks can be used to perform pre-processing before the
state_dictcall is made.
- requires_grad_(requires_grad=True)
Change if autograd should record operations on parameters in this module.
This method sets the parameters’
requires_gradattributes in-place.This method is helpful for freezing part of the module for finetuning or training parts of a model individually (e.g., GAN training).
See Locally disabling gradient computation for a comparison between .requires_grad_() and several similar mechanisms that may be confused with it.
- Return type:
Self
- Args:
- requires_grad (bool): whether autograd should record operations on
parameters in this module. Default:
True.
- Returns:
Module: self
- set_extra_state(state)
Set extra state contained in the loaded state_dict.
This function is called from
load_state_dict()to handle any extra state found within the state_dict. Implement this function and a correspondingget_extra_state()for your module if you need to store extra state within its state_dict.- Return type:
- Args:
state (dict): Extra state from the state_dict
- set_submodule(target, module, strict=False)
Set the submodule given by
targetif it exists, otherwise throw an error. :rtype:NoneNote
If
strictis set toFalse(default), the method will replace an existing submodule or create a new submodule if the parent module exists. Ifstrictis set toTrue, the method will only attempt to replace an existing submodule and throw an error if the submodule does not exist.For example, let’s say you have an
nn.ModuleAthat looks like this:A( (net_b): Module( (net_c): Module( (conv): Conv2d(3, 3, 3) ) (linear): Linear(3, 3) ) )(The diagram shows an
nn.ModuleA.Ahas a nested submodulenet_b, which itself has two submodulesnet_candlinear.net_cthen has a submoduleconv.)To override the
Conv2dwith a new submoduleLinear, you could callset_submodule("net_b.net_c.conv", nn.Linear(1, 1))wherestrictcould beTrueorFalseTo add a new submodule
Conv2dto the existingnet_bmodule, you would callset_submodule("net_b.conv", nn.Conv2d(1, 1, 1)).In the above if you set
strict=Trueand callset_submodule("net_b.conv", nn.Conv2d(1, 1, 1), strict=True), an AttributeError will be raised becausenet_bdoes not have a submodule namedconv.- Args:
- target: The fully-qualified string name of the submodule
to look for. (See above example for how to specify a fully-qualified string.)
module: The module to set the submodule to. strict: If
False, the method will replace an existing submoduleor create a new submodule if the parent module exists. If
True, the method will only attempt to replace an existing submodule and throw an error if the submodule doesn’t already exist.- Raises:
ValueError: If the
targetstring is empty or ifmoduleis not an instance ofnn.Module. AttributeError: If at any point along the path resulting fromthe
targetstring the (sub)path resolves to a non-existent attribute name or an object that is not an instance ofnn.Module.
See
torch.Tensor.share_memory_().- Return type:
Self
- state_dict(*args, destination=None, prefix='', keep_vars=False)
Return a dictionary containing references to the whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are included. Keys are corresponding parameter and buffer names. Parameters and buffers set to
Noneare not included.Note
The returned object is a shallow copy. It contains references to the module’s parameters and buffers.
Warning
Currently
state_dict()also accepts positional arguments fordestination,prefixandkeep_varsin order. However, this is being deprecated and keyword arguments will be enforced in future releases.Warning
Please avoid the use of argument
destinationas it is not designed for end-users.- Args:
- destination (dict, optional): If provided, the state of module will
be updated into the dict and the same object is returned. Otherwise, an
OrderedDictwill be created and returned. Default:None.- prefix (str, optional): a prefix added to parameter and buffer
names to compose the keys in state_dict. Default:
''.- keep_vars (bool, optional): by default the
Tensors returned in the state dict are detached from autograd. If it’s set to
True, detaching will not be performed. Default:False.
- Returns:
- dict:
a dictionary containing a whole state of the module
Example:
>>> # xdoctest: +SKIP("undefined vars") >>> module.state_dict().keys() ['bias', 'weight']
- to(*args, **kwargs)
Move and/or cast the parameters and buffers.
This can be called as
- to(device=None, dtype=None, non_blocking=False)
- to(dtype, non_blocking=False)
- to(tensor, non_blocking=False)
- to(memory_format=torch.channels_last)
Its signature is similar to
torch.Tensor.to(), but only accepts floating point or complexdtypes. In addition, this method will only cast the floating point or complex parameters and buffers todtype(if given). The integral parameters and buffers will be moveddevice, if that is given, but with dtypes unchanged. Whennon_blockingis set, it tries to convert/move asynchronously with respect to the host if possible, e.g., moving CPU Tensors with pinned memory to CUDA devices.See below for examples.
Note
This method modifies the module in-place.
- Args:
- device (
torch.device): the desired device of the parameters and buffers in this module
- dtype (
torch.dtype): the desired floating point or complex dtype of the parameters and buffers in this module
- tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
- memory_format (
torch.memory_format): the desired memory format for 4D parameters and buffers in this module (keyword only argument)
- device (
- Returns:
Module: self
Examples:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> linear = nn.Linear(2, 2) >>> linear.weight Parameter containing: tensor([[ 0.1913, -0.3420], [-0.5113, -0.2325]]) >>> linear.to(torch.double) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1913, -0.3420], [-0.5113, -0.2325]], dtype=torch.float64) >>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_CUDA1) >>> gpu1 = torch.device("cuda:1") >>> linear.to(gpu1, dtype=torch.half, non_blocking=True) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1914, -0.3420], [-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1') >>> cpu = torch.device("cpu") >>> linear.to(cpu) Linear(in_features=2, out_features=2, bias=True) >>> linear.weight Parameter containing: tensor([[ 0.1914, -0.3420], [-0.5112, -0.2324]], dtype=torch.float16) >>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble) >>> linear.weight Parameter containing: tensor([[ 0.3741+0.j, 0.2382+0.j], [ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128) >>> linear(torch.ones(3, 2, dtype=torch.cdouble)) tensor([[0.6122+0.j, 0.1150+0.j], [0.6122+0.j, 0.1150+0.j], [0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
- to_empty(*, device, recurse=True)
Move the parameters and buffers to the specified device without copying storage.
- Return type:
Self
- Args:
- device (
torch.device): The desired device of the parameters and buffers in this module.
- recurse (bool): Whether parameters and buffers of submodules should
be recursively moved to the specified device.
- device (
- Returns:
Module: self
- train(mode=True)
Set the module in training mode.
This has an effect only on certain modules. See the documentation of particular modules for details of their behaviors in training/evaluation mode, i.e., whether they are affected, e.g.
Dropout,BatchNorm, etc.- Return type:
Self
- Args:
- mode (bool): whether to set training mode (
True) or evaluation mode (
False). Default:True.
- mode (bool): whether to set training mode (
- Returns:
Module: self
- type(dst_type)
Casts all parameters and buffers to
dst_type. :rtype:SelfNote
This method modifies the module in-place.
- Args:
dst_type (type or string): the desired type
- Returns:
Module: self
- xpu(device=None)
Move all model parameters and buffers to the XPU.
This also makes associated parameters and buffers different objects. So it should be called before constructing optimizer if the module will live on XPU while being optimized. :rtype:
SelfNote
This method modifies the module in-place.
- Arguments:
- device (int, optional): if specified, all parameters will be
copied to that device
- Returns:
Module: self
- zero_grad(set_to_none=True)
Reset gradients of all model parameters.
See similar function under
torch.optim.Optimizerfor more context.- Return type:
- Args:
- set_to_none (bool): instead of setting to zero, set the grads to None.
See
torch.optim.Optimizer.zero_grad()for details.